Rの使い方
導入〜さあ、データをRで解析しよう!
題材
使うデータ
下準備
Rの導入
- CRANのページから最新版のRを入手します。
- .exeファイルをダウンロードし、アイコンをダブルクリックします。
- インストールする途中で、インストールするコンポーネントを選択するところがあるので、「全てインストール」を選択します。
- 「起動時オプション」は「はい」にして、カスタマイズします。「表示モード」はSDIに、「ヘルプの表示方法」は「テキスト形式」に変更してください。あとはそのまま進んでください。
- 最初にRを起動したときに、文字が化けていることがあります。この場合、Rの上にある「編集」→「GUIプリファレンス」とたどると、新しくウィンドウが表示されます。ここの「Font」を「MS Gothic」に変え、下のほうの「適用」をクリックした後、「保存」をクリックしてください(ファイルネームは初期値のRconsoleそのままでいいです)。保存場所は、最初に表示されるフォルダにそのまま保存してください。
- Windows Vistaの方で、上記のRconsoleがRの作業フォルダに直接保存できない場合、一度デスクトップに保存し、手動でRconsoleをRの作業フォルダに移してください。
データファイルの作り方

以下のように並べてしまうと、Rでの作業には適していません。

その他、以下の点に注意して下さい。
- ゑくせるなどにデータを打ち込む。
- 各列に個体番号、環境条件などを入れる。
- 1 行目にはデータのラベルを入力する。
- 日本語、特殊文字(% や○×など)は絶対に使わない。入力していいのは、数字、半角英文字のみ(生残なら0 と1 で区別する)。
- 基本的に空のセルを作らない。欠損値は、NAを入力しておく。
- 違った形式(並べ方が異なる)のデータを同一ファイル内に混在させない。
作ったデータの置き場
- 基本的にはどこでもいいです。ただ、トラブルが起きる確率を最小限にするのであれば、日本語やスペースなどが入っているフォルダの下には置かないで下さい。
- Windowsの方:Rを起動して、「ファイル」→「ディレクトリの変更」と進んで、そのファイルがあるフォルダを指定します。
- Macの方:Rを起動して、「その他」→「作業ディレクトリの変更」と進んで、ファイルがあるフォルダを指定します。
Rでのデータ操作
Rへのデータの読み込ませ方
Rを起動すると、
>
Rでは、マウスでかちかちしてデータを読み込んだりすることはできません。この状態で、「ファイルを読み込んで」「図を作って」といった、コマンドを打ち込んで動作させます。ちょっと古いパソコンみたいですね。慣れないとしんどいと思いますが、頑張りましょう。
> d <- read.csv("base.csv")
このように打ち込んでEnterを押して、特に何も言われなければ問題なく読み込めました。その場合は、以下のように打ち込んで下さい。base.csvの内容が表示されるはずです。
> d
- dという文字は、別にどんな名前でもよい。この、適当な文字列を、Rでは、「 オブジェクト 」と呼ぶ。
- Rでは、オブジェクトにデータをくっつけて作業をする。
- オブジェクトの名前は自分で好きに決めることができるが、数字が最初に来る名前は付けられない(だめな例:0704iijima)。
- read.csv("")は、csv形式のファイルを読み込みなさい、という命令である。
逆に、何かエラーが出てしまった方は、以下の点を確認しましょう。
- 打ち込んだスペルはあっているか?
- データ(base.csv)のある場所が、Rにちゃんと指定されていない。ディレクトリの変更で、ちゃんとbase.csvがある場所を指定しているか?
- 日本語が入力できる状態で入力していないか(例えば<-は半角の<と-を続けて書くことで書いているが、日本語モードで変換して半角の<を出していないか)?Rでは半角英数文字しか受け付けない。
エラーなく読み込めたら、このデータを色々いじっていきます。なお、これ以降のコマンドでは「>」を省略します。
- 上で見たように、Rではコマンドを打ち込んで動作させます。この後、どんどん複雑なコマンドが必要になってきます。そのため、Rに直接コマンドを打ち込むのではなく、 メモ帳やWordなどに必ずコマンドを下書きし、Rにコピペして命令を出すようにして下さい 。
- :を使うと、1ずつ変化する数列(等差数列)を生成できます。例えば、1:10と打ち込むと、1から10までの数列が生成されます。いろんな所で使うので、覚えておきましょう。
データの概要をつかむ
- head():データフレームの上6行を取り出す。下6行についてはtail()。取り出す行数は、引数で調整可能。
- nrow():データの行数を出してくれる。列数についてはncol()。
- summary():各列の基礎的な統計量を出力。いろんな所で使う関数。
- pairs():列同士の散布図を出力。
データの先頭行を見るhead()
head(d) Plot Sp DBH02 DBH04 DBH06 DBH08 DBH10 1 PlotA Sp56 14.773116 16.737987 19.31643 24.61452 NA 2 PlotA Sp46 10.959117 13.831113 17.40913 23.60213 30.27258 3 PlotA Sp60 6.136076 7.385640 NA NA NA 4 PlotA Sp35 17.835907 18.786075 22.41280 NA NA 5 PlotA Sp12 6.786937 8.408327 10.81423 14.00716 17.75146 6 PlotA Sp03 16.309994 20.569902 27.04936 35.76303 43.93186
- Plot:調査プロット名
- Sp:樹種
- DBH02:2002年の胸高直径。
- DBH04:2004年の胸高直径。死亡した個体にはNAが入力されている。以下同様
データの大きさ(行や列の数)を見るnrow()やncol()
nrow(d) #行数 [1] 10000 ncol(d) #列数 [1] 7
各列のデータの概要をつかむsummary()
summary(d)
Plot Sp DBH02 DBH04
PlotP : 453 Sp57 :1206 Min. : 3.000 Min. : 3.943
PlotQ : 453 Sp26 : 934 1st Qu.: 6.904 1st Qu.: 8.968
PlotK : 448 Sp07 : 564 Median : 9.942 Median : 13.007
PlotV : 445 Sp12 : 521 Mean : 12.868 Mean : 16.712
PlotS : 443 Sp21 : 513 3rd Qu.: 15.458 3rd Qu.: 20.085
PlotD : 432 Sp56 : 488 Max. :162.271 Max. : 181.787
(Other):7326 (Other):5774 NA's :4000.000
DBH06 DBH08 DBH10
Min. : 5.118 Min. : 6.743 Min. : 8.68
1st Qu.: 11.981 1st Qu.: 15.805 1st Qu.: 20.69
Median : 17.344 Median : 22.754 Median : 29.24
Mean : 21.817 Mean : 27.811 Mean : 34.99
3rd Qu.: 26.531 3rd Qu.: 34.262 3rd Qu.: 43.04
Max. : 202.500 Max. : 224.257 Max. : 247.00
NA's :5294.000 NA's :5762.000 NA's :5999.00
データ同士の関係を図で見るpairs()
pairs(d)

データの部分的な抽出
- データフレーム[行, 列]:行や列に当たる部分に、数字、列や行の名前、条件式などを入れて、それに従う部分だけを取り出す(とても重要!)
- データフレーム$列名:特定の列を取り出す。
- split():データフレームを、あるカテゴリーを示す列ごとに分割する。ゑくせるで言うところのオートフィルタに近い。
- colnames():データフレームの列名を取り出す。仲間にrownames()。
- plot():いわゆる散布図を描く。2編量感の関係を見るのに便利。
- xyplot():同じく散布図だが、カテゴリーごとの図を作るのに便利。library(lattice)で呼び出す。
行列の要素の指定による部分抽出
d[, 1] #1列目だけが取り出される d$Plot #列名を指定した場合 d[, "Plot"] #これでも同じ
列を削除する場合は、列の番号にマイナスをつけるか、NULLを代入します。
d[, -1] #1列目だけが抜けている
d$DBH02 <- NULL
head(d) #DBH02が削除されている
d <- read.csv("base.csv") #元に戻す
列を加える場合は、新しい列名に入るデータを代入します。
d$newdata <- d$DBH02 * 2 #DBH02を2倍したデータ head(d) #データが増えている d$newdata <- NULL #いらないんで削除
特定の条件でデータを取り出すには、以下のようにします。
d[d$DBH02 >= 50, ] #DBHが50cm以上の個体のみを取り出す d[d$Sp == "Sp04", ] #SpがSp04のみ取り出す
d$DBH02 >= 50 [1] FALSE FALSE FALSE (以下略)
条件式の書き方
- a == b:aとbは等しい
- a != b:aとbは等しくない
- a > b:aはbより大きい
- a >= b:aはb以上
- a < b:aはbより小さい
- a <= b:aはb以下
- a | b:aまたはb
- a & b:aおよびb
カテゴリーごとにデータを分割するsplit()
カテゴリーごとにデータを取り出す場合、ある 1つを取り出すなら上記の方法でいいですが、いくつかのカテゴリーのデータが欲しくなると、1つ1つ指定して取り出すのは面倒になってきます。その場合に、以下の関数を走らせるとカテゴリーごとにデータを分割できます。split()でデータを分割すると、カテゴリーの順番を示す数字、またはカテゴリー名でデータを取り出すことができます。
d2 <- split(d, d$Sp) d2[[3]] #Sp03のデータだけが取り出されている d2[["Sp03"]] #同じことを、カテゴリー名で
行名、列名の取り出し方
データが大きくなると、とりあえず列や行の名前だけ取り出したくなることもあります。その場合は、以下のようにします。
colnames(d) #列名 rownames(d) #行名
取り出したデータの視覚化
plot(DBH04 ~ DBH02, d) #y ~ xという関係。 #Sp3だけに限定した図 plot(DBH04 ~ DBH02, d2[[3]]) #先ほどのsplit()の結果を利用して
boxplot(DBH02 ~ Plot, d)
ちなみに、先ほどの散布図を何かのカテゴリーごとに描きたい(例えばPlotごととか)場合は、latticeパッケージのxyplot()を使います。
library(lattice) xyplot(DBH04 ~ DBH02 | Plot, d) #|の後ろに、カテゴリー名を入れます。

時系列データの図化
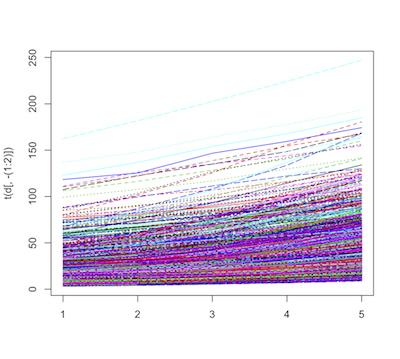
今回のデータは、時系列データです。それなら、時間に沿った変化を見たいところです。時系列な変化を作図するときは、matplot()を使います。
matplot(t(d[, -(1:2)]), type="l")
- matplot()は、 各行が各自系列の時点 (今回で言うと年)になっていないといけません。しかし今回のデータは、列(横方向)に年が並んでいます。
- t()は、転置行列(データフレームの行列を入れ替える)を行ってくれる関数です。
- そこで、t(d[, -(1:2)])とすることで、元々のデータフレームの行列を入れ替えています(1〜2列目はプロット名と種名なので作図に入らないので除いておく)。
パッケージの読み込み
- Windows:「パッケージ」→「パッケージのインストール」と進み、ダウンロードするミラーサーバを選ぶ(どこでもよい)。その後、パッケージの一覧が表示されるので、必要なパッケージを選択してOKを押す(Ctrlキーで複数選択可能)。
- Mac:「パッケージとデータ」→「パッケージインストーラ」とすすみ、パッケージ名を「パッケージ検索」の所に入力して検索。必要なパッケージが表示されたら「選択をインストール」からインストールする。
データの集計
- mean():平均値を算出する。
- sd():標準偏差を算出する。
- min():最小値を算出する。
- max():最大値を算出する。
- table():カテゴリー数を算出する。
- xtabs():カテゴリーごとに値を集計(2カテゴリー以上で力を発揮)。
- tapply():カテゴリーごとに関数を適用。ゑくせるで言うところのピボットテーブルに当たる。
平均値、標準偏差、最小値、最大値を算出する
基本的には、関数に統計量を算出したいデータを入れれば動作します。以下では平均値の齢を示しますが、標準偏差や最大値なども同様です。
mean(d$DBH02)
カテゴリー数の算出
カテゴリーの列があると、それぞれのカテゴリーがいくつあるか知りたくなることがあります(各プロットに含まれる個体数とか)。カテゴリーごとのデータ数を知るためには、以下のようにします。
table(d$Plot) #2変数以上に拡張 xtabs(~ Plot + Sp, d)
ちなみに、xtabs()は、~の前にデータを入れることで、カテゴリーごとの合計値を出すこともできます。例えば「プロット」かつ「種」ごとのDBH02の合計値を知りたいときは、以下のようにすれば算出できます。
xtabs(DBH02 ~ Plot + Sp, d)
カテゴリーごとに関数を適用
結構多用します。具体的には、「種ごとのDBHの平均値を知りたい」「プロットごとに最大個体サイズを出したい」などといった状況です。最初の例を実行する方法を以下に示します。
tapply(d$DBH02, d$Sp, mean)
Sp01 Sp02 Sp03 Sp04 Sp05 Sp06 Sp07
13.511304 11.961657 14.638334 12.679400 10.904242 12.664050 12.940691
(以下省略)
tapply()は、(関数を適用するデータ, カテゴリー, 関数)という書き方になります。これは当然、2カテゴリー以上でも動作します。
tapply(d$DBH02, d[, c("Plot", "Sp")], mean)
Sp
Plot Sp01 Sp02 Sp03
PlotA 9.636401 11.132252 16.309994
PlotB 8.404061 9.444711 16.000510
(以下略)
動作させる関数には、なにか計算する関数だけではなくて作図関数なども適用できます。
par(mfrow=c(5, 5), mar=c(2, 2, 1, 1)) #作図関係のおまじない tapply(d$DBH02, d$Plot, hist, main="")
データの呼び方
ちょっと意識しにくいかも知れませんが、Rではデータ一つをとっても、形や並び方によって様々な呼び方をします。ここでは、データの呼び方をはっきりさせておきましょう。

1つのデータの種類
- 数字:numeric。1、3.5、-10など
- 文字列:character。"Tekito"、"Darui"など。
- 要因:factor。見た目は文字列っぽいのだが、水準(順位)が付いている。例えば本データ中のSp(d$Sp)は要因。
- 論理値:logical。TRUEまたはFALSE。
- 欠損:NA。これが入っていると動作しない関数があるので要注意(後述)。
- 非数:NaN。1/0とかやっちゃったりすると発生する。やっぱり関数の動作を妨げるので要注意。
集まりとしてのデータの種類
- ベクトル:c()。構造などがない一つながりのデータ。あらゆる種類のデータを含めるが、 同一ベクトル内で異なった形式の値を混在させることはできない 。むりくり異なった形式の値を混在させると、一番ランクの低い形式に合わされる。例えば、文字列が入っている場合は数字も文字列扱いになってしまう。
test <- c(1, 2, "Tekito", TRUE) test [1] "1" "2" "Tekito" "TRUE" test[1] + test[2] Error in test[1] + test[2] 1 + 2 [1] 3
- 行列:matrix()。行列(縦と横)の形があるデータ。数字以外は含めない。
- データフレーム:data.frame()。見た目は行列だが、数字以外も含める。実用的には最も多用する形式。行や列のラベルあるいは番号で行や列を取り出せる。行数の違う列が混在することはできない。
- リスト:list()。構造や並び方が違うデータも無理矢理一つにできる。自分で作ることはあんまり無いが、統計や作図関数の結果を返したオブジェクトはリストになっていることが多い。
データフレームの保存の仕方
上記のようにしていじったデータフレームは、ファイルとして保存できます。たとえばd2というオブジェクトにいじった結果がくっついているとしたら、以下のようにして保存できます。保存場所は、現在の作業ディレクトリです。
write.csv(d2, file="new.csv", row.names=F) #new.csvというファイルとして保存。
欠測値NAへの対応
あれー?
mean(d$DBH04) [1] NA
- 関数の引数で対応。
- NAを除去する。
- NAを0に変換してしまう(欠損であることが0と等価である場合のみ有効)
関数の引数で対応
関数によっては、引数でNAを除いて実行することが可能です。
mean(d$DBH04, na.rm=TRUE)
NAを除去する
- na.omit():NAを含む行を削除する。
- is.na():NAならTRUE、そうでなければFALSEを返す
nrow(d) #もともとのデータの行数 d3 <- na.omit(d) nrow(d3) [1] 4001 #NAを含む行が除かれ、行数が減少している summary(d3) #NAがDBHのどのデータにも含まれていない
d[d$DBH04 != NA, ] #今までの知識ならこれで判定できそうだが......
Plot Sp DBH02 DBH04 DBH06 DBH08 DBH10
NA NA NA NA NA NA
NA.1 NA NA NA NA NA
NA.2 NA NA NA NA NA
(以下略)
といったように、NAかどうかを判定するためには、それ専用の関数が必要になります。
is.na(d$DBH04)
こうすると、とりあえずNAかどうかは判定できているようです。で、今はNAでない部分が欲しいので、否定である!をつけて、以下のようにします。
d[!is.na(d$DBH04), ]
NAを0に変換する
d$DBH04a <- ifelse(is.na(d$DBH04), 0, d$DBH04)
上記からわかるように、ifelse()はifelse(条件式, TRUEの場合, FALSEの場合)という書き方になります。
NAから生残データを生成
d$S04 <- ifelse(is.na(d$DBH04), 0, 1)
データ同士の結合
Aさんは過去からの測定データを受け継いだわけですが、自らの研究でただ続きの成長・生残データを取るだけではつまらないと思いました。そこで、調査地ごとの光環境と水分条件を測定しました(環境データはこちら)。
e <- read.csv("env.csv")
head(e)
Plot Light Water
1 PlotA 0.4847369 19.98155
2 PlotB 0.5566825 21.83956
(以下略)
d2 <- merge(d, e)
head(d2, 2)
Plot Sp DBH02 DBH04 DBH06 DBH08
1 PlotA Sp56 14.773116 16.737987 19.31643 24.61452
2 PlotA Sp46 10.959117 13.831113 17.40913 23.60213
DBH10 S10 Light Water
1 NA 0 0.4847369 19.98155
2 30.27258 1 0.4847369 19.98155
データ解析
データの図化
まずは、必要なデータを読み込みます。
d <- read.csv("base.csv")
#生残データを作る
d$S10 <- ifelse(is.na(d$DBH10), 0, 1)
#環境データを読み込んで結合
e <- read.csv("env.csv")
d2 <- merge(d, e)
生残
では、実際に生残と考えている要因の関係がどうなっているか、見てみましょう。
par(mfrow=c(2,2)) plot(S10 ~ DBH02, d2) plot(tapply(d2$S10, d2$Sp, mean)) plot(tapply(d2$Light, d2$Plot, mean), tapply(d2$S10, d2$Plot, mean)) plot(tapply(d2$Water, d2$Plot, mean), tapply(d2$S10, d2$Plot, mean))

種によって生残率が異なり、明るく乾燥しているほど生残率は高いように見受けられます。しかし、複数の要因が同時に作用しているため、これらの作図だけではどの要因が成長や生残に影響しているのか判然としません。
現象をモデル化する
統計モデルの部品〜決定論的モデルと確率論的モデル
- 決定論的モデル:説明変数と応答変数の関係性を示したもの。自分がどう現象を捉えているかといってもいい。
- 確率論的モデル:得られる現象がどのような確率的変動をもって生じるかに関する仮説。
統計的モデリングを行ううえで、これらの存在を意識することが重要です。決定論的モデルはそれぞれの現象に対して研究者が考えることですので、ここでは確率論的モデルについて紹介したいと思います。
確率論的モデル
- 測定誤差
- 観測できない要因の影響

- 1行目:データ
- 2行目:データと、決定論的モデルでの予測値(線)
- 3行目:決定論的モデルと想定している誤差の分布
決定論的モデルに含まれる要因の係数(切片や傾き)は、データを最もよく説明できるように決定されます。では、「データを最もよく説明できる」基準とはなんでしょうか?
尤度
尤度とは、あるデータが得られたときに、ある確率分布の元でデータをどれだけ尤もらしく表現できているかを示すもの(確率ではありません)です。前の節で、データを最もよく説明できる基準に基づいて決定論的モデルに含まれる要因の計数を決定すると説明しました。尤度は、この基準として用います。
確率分布は様々な種類があります。確率分布は「パラメータ」を持ち、このパラメータを変化させることで、分布の形が変わります。具体的な例を挙げると、正規分布では平均と分散という2つのパラメータ、二項分布では生起確率という1つのパラメータを持ちます。
Aさんが今解析したいと思っているのは、樹木の生残にどのような要因が影響しているか?です。生残する確率は最大でも1、最低でも0です。このようなデータは、二項分布に従うと考えるのが適当です。二項分布は、以下のような分布です。
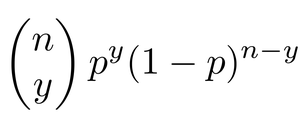
ここで、nは総試行回数、yは事象が生起した回数、pは生起確率です。この分布にデータを入れると、どうなるでしょうか?
(注!移転途中)